Research

Visual Experience Database
 It is widely believed that our
visual system is honed by the statistics of our visual experience.
However, large-scale image databases are sampled from the web, and may
not reflect lived experiences. Together with Ben Balas at
NDSU and the MacNeilage and Lescroart labs at UNR, and supported
by the NSF we have amassed one of the largest and most
representative datasets of first-person video, complete with head- and
eye-movements.
It is widely believed that our
visual system is honed by the statistics of our visual experience.
However, large-scale image databases are sampled from the web, and may
not reflect lived experiences. Together with Ben Balas at
NDSU and the MacNeilage and Lescroart labs at UNR, and supported
by the NSF we have amassed one of the largest and most
representative datasets of first-person video, complete with head- and
eye-movements.
Bibliography
Greene, M. R., Balas, B. J., Lescroart, M. D., MacNeilage, P. R., Hart, J. A., Binaee, K., Hausamann, P. A., Mezile, R., Shankar, B., Sinnott, C. B., Capurro, K., Halow, S., Howe, H., Josyula, M., Li, A., Mieses, A., Mohamed, A., Nudnou, I., Parkhill, E., … Weissmann, E. (2024). The Visual Experience Dataset: Over 200 Recorded Hours of Integrated Eye Movement, Odometry, and Egocentric Video (arXiv:2404.18934). arXiv.
Global Scene Properties

My research challenges the notion that scenes are merely a collection of
objects. Instead, I have found that global aspects of scene geometry and
affordance make better primitives than objects. I have termed such
properties global properties because they cannot be computed
from a local segment of the image. The first paper in this series
demonstrated that human observers are more
sensitive to global properties that describe a scene’s layout and
functions than the objects within them. We further found that
observers need less
viewing time (on average) to assess a scene’s global properties than
even to categorize it at the basic level. Finally, global scene
properties can undergo selective adaptation, and being
in an adapted state alters scene categorization patterns.
Furthermore, global properties can be perceived very well in the far periphery, and patterns of activity in the parahippocampal place area (PPA) seem to follow the similarity patterns of global properties.
Bibliography
Greene, M. R., & Oliva, A. (2009). Recognition of natural scenes from global properties: Seeing the forest without representing the trees. Cognitive Psychology, 58(2), 137-176.
Greene, M. R., & Oliva, A. (2009). The briefest of glances: The time course of natural scene understanding. Psychological Science, 20(4), 464-472.
Greene, M. R., & Oliva, A. (2010). High-level aftereffects to global scene properties. Journal of Experimental Psychology: Human Perception and Performance, 36(6), 1430.
Park, S., Brady, T. F., Greene, M. R., & Oliva, A. (2011). Disentangling scene content from spatial boundary: complementary roles for the parahippocampal place area and lateral occipital complex in representing real-world scenes. Journal of Neuroscience, 31(4), 1333-1340.
Boucart, M., Moroni, C., Thibaut, M., Szaffarczyk, S., & Greene, M. (2013). Scene categorization at large visual eccentricities. Vision Research, 86, 35-42.
Scene Affordances

Category labels provide information on the “joints” that we use to carve
up our visual world. What is the fundamental principle by which we
assign environments to their categories? I am particularly interested in
a functional definition of category – that is, that scene
category boundaries are determined by the types of actions that one can
perform in the scene. In other words, a scene’s affordances determine
its category. Using a massive crowdsourced dataset of over 5 million
images, my colleagues and I have demonstrated that scene
categorization patterns are better explained by these scene functions
than by objects or perceptual features.
Although functions explain comparatively little variance in the response properties of scene-selective areas such as the PPA, RSC, or OPA, they do explain earlier variability in event-related potentials (ERPs). We are about to submit the full manuscript of this work - watch this space!
Bibliography
Greene, M. R., Baldassano, C., Esteva, A., Beck, D. M., & Fei-Fei, L. (2016). Visual scenes are categorized by function. Journal of Experimental Psychology: General, 145(1), 82.
Groen, I. I., Greene, M. R., Baldassano, C., Fei-Fei, L., Beck, D. M., & Baker, C. I. (2018). Distinct contributions of functional and deep neural network features to representational similarity of scenes in human brain and behavior. Elife, 7, e32962.
Greene, M. R., & Hansen, B. C. (2018). From Pixels to Scene Categories: Unique and Early Contributions of Functional and Visual Features. Computational Cognitive Neuroscience.
Top-down Scene Understanding

What we see is not only a function of the visual features entering our eyes, but also our knowledge and expectations of what we think we will see. These expectations govern how well we will see an image. In other words, if we don’t see it often, we often don’t see it. We tested this by comparing images of common, everyday content with visually-matched images that depicted low-probability events from the world (see above for examples).When comparing unusual images and matched controls in a demanding detection task, observers were significantly more accurate at detecting the control pictures compared to the unusual ones, even though no machine vision system could distinguish between them.
One recent method I have employed for assessing top-down contributions to visual processing is in comparing human scene representations to those of deep, convolutional neural networks (dCNNs). This is because these models contain no feedback information, despite achieving categorization accuracies that rival those of human observers. Recently, we have shown that the order of representational transformations in a dCNN is similar to those observed in human EEG patterns.
Together with my students, we have been extending these findings to assess the neural decoding implications for images that are easy for dCNNs to classify versus those that are difficult. Our work is showing that images that are difficult for dCNNs also take human observers longer in terms of reaction time, but also contain far less decodable category information that easy images (Siegart, Zhou, Machoko, Lam & Greene, VSS 2019). Watch this space for the pre-print!
Bibliography
Greene, M. R., Botros, A. P., Beck, D. M., & Fei-Fei, L. (2015). What you see is what you expect: rapid scene understanding benefits from prior experience. Attention, Perception, & Psychophysics, 77(4), 1239-1251.
Greene, M. R., & Hansen, B. C. (2018). Shared spatiotemporal category representations in biological and artificial deep neural networks. PLoS Computational Biology, 14(7), e1006327.
Category Structure

Jerome Bruner noted that every act of recognition is an act of categorization. To what extent is this literally true? To tackle this question, I used a modified Stroop paradigm in which observers viewed words superimposed over pictures of objects and scenes, and were asked to classify the word as describing a type of object or a type of scene. Although the images were irrelevant to performance, category names that were incongruent with the pictures were classified slower and less accurately than those with the conguent picture, suggesting that visual categorization is an automatic process.
Our mental models of objects and scenes contain a good deal of predictable structure. One type of structure is vertical: my cat is also part of more broad categories like mammal and vertebrate, and also more specific categories like American shorthair tabby. However, when referring to him, most people use the middle level of specificity (i.e. “cat”). This is known as the basic-level or entry-level category effect. What is striking about this effect is how seemingly natural it is to classify entities this way despite sometimes broad physical differences among members. For example, that we group both Pekinese and Corgis as dogs even when the Pekinese might share more physical properties with cats. In investigating the neural correlates of this effect, my colleagues and I have found that the object-selective lateral occipital complex (LOC) has response properties that are more correlated with behaviorally-derived similarity than physical similarity.
Our category structures are also horizontal: within each category, some members seem to be better representatives of the category than others. For example, a Golden Retriever may seem like a prototypical exemplar of the “dog” category. Using similar methods as described above, we found that LOC also reflects the typicality assessments of human observers. Ongoing work in my lab is extending these questions with EEG in order to determine the time course of category evolution.
I have recently written a review chapter on visual category structure. Please check it out!
Bibliography
Greene, M. R., & Fei-Fei, L. (2014). Visual categorization is automatic and obligatory: Evidence from Stroop-like paradigm. Journal of Vision, 14(1), 14-14.
Iordan, M. C., Greene, M. R., Beck, D. M., & Fei-Fei, L. (2015). Basic level category structure emerges gradually across human ventral visual cortex. Journal of Cognitive Neuroscience, 27(7), 1427-1446.
Iordan, M. C., Greene, M. R., Beck, D. M., & Fei-Fei, L. (2016). Typicality sharpens category representations in object-selective cortex. Neuroimage, 134, 170-179.
Greene, M. R. (2019). The information content of scene categories.. In Federmeier & Beck (eds) Knowledge and Vision: Volume 70.
Object-Scene Context
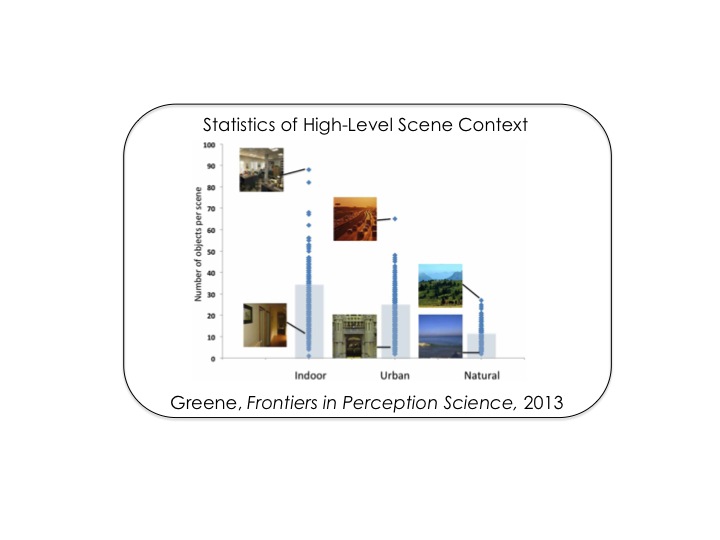
Scenes are complex, but not random. We know that keyboards tend to be
found below monitors, and that chimneys are not found on the lawn. While
many vision scientists believe that this contextual knowledge aids
recognition, we cannot understand the extent to which it helps without
first measuring how much redundancy there is. Though mining a large,
fully-labeled scene database, I
have provided a first set of contextual statistics, including object
frequency and conditional frequencies based on scene category.
The next logical step is to understand how human observers internalize these contextual statistics. I asked observers to rate the frequency with which various objects could be found in various scenes. Across six experiments, I found that object frequency was systematically over-estimated by an average of 32%.
Of course, any bias in one’s sample biases one’s statistics. In assessing pictures found on the web, it’s easy to notice that the images that we choose to share with others do not necessarily reflect the raw statistics of our visual experience. To this end, I am working towards amassing larger and more visually-representative data, and using computer vision to help scale the annotation work. Watch this space!
Bibliography
Greene, M. R. (2013). Statistics of high-level scene context. Frontiers in Psychology, 4, 777.
Greene, M. R. (2016). Estimations of object frequency are frequently overestimated. Cognition, 149, 6-10.
Visual Search in Scenes

How do I find my lost keys? Visual search for real objects in real scenes does not always follow the same laws as visual search displays that are frequently used in experiments. In particular, the number of objects in a scene has very little influence over the difficulty of the search. In seeking to understand why this is the case, my colleagues and I have put forth a two pathway theory whereby a non-selective and global analysis of the scene can allow for activations of possible object locations while a selective process can evaluate each location in a serial manner.
The ways in which we search a scene depend on what we are looking for, where we are, and who we are. Using pattern classification techniques, we have shown that summary statistics of eye movements can predict what one is seeing, and the observer that produced the eye movements. However, predicting the observer’s task from the eye movements was not possible with these methods.
Bibliography
Wolfe, J. M., Võ, M. L. H., Evans, K. K., & Greene, M. R. (2011). Visual search in scenes involves selective and nonselective pathways. Trends in Cognitive Sciences, 15(2), 77-84.
Greene, M. R., Liu, T., & Wolfe, J. M. (2012). Reconsidering Yarbus: A failure to predict observers’ task from eye movement patterns. Vision Research, 62, 1-8.